1.1. Phân loại và biểu diễn thông tin trong máy tính
– Khi đưa vào máy tính thông tin được chuyển thành dữ liệu. Dữ liệu trên máy cũng cần được phân loại cho phù hợp với các phép xử lí trong máy tính. Ví dụ, đối với các dữ liệu là số có thể tính toán và so sánh. Còn đối với các dữ liệu dạng văn bản thì có thể tách, ghép, so sánh.
– Việc mã hoá thông tin thành dữ liệu nhị phân được gọi là biểu diễn thông tin. Biểu diễn thông tin là bước đầu để có thể đưa thông tin vào máy tính.
|
– Biểu diễn thông tin trong máy tính là cách mã hoá thông tin. – Các kiểu dữ liệu thường gặp là văn bản, số hình ảnh, âm thanh và lôgic. – Việc phân loại dữ liệu để có cách biểu diễn phù hợp nhằm tạo thuận lợi đó việc xử lý thông tin trong máy tính. |
|---|
– Hình 3.2 là sơ đồ phân loại các kiểu dữ liệu được đề cập trong chương trình tin học phổ thông
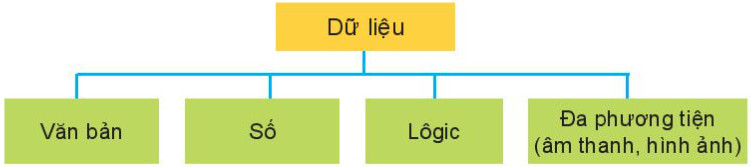
Hình 3.2. Sơ đồ phân loại các kiểu dữ liệu
1.2. Biểu diễn dữ liệu văn bản
a) Bảng mã ASCII
– Bảng mã ASCII mở rộng sử dụng 8 bit để biểu diễn một kí tự.
– Bảng mã được dùng phổ biến nhất trong tin học là “bảng mã chuẩn của Mỹ để trao đổi thông tin” (American Standard Code for Information Interchange viết tắt là ASCII).
– Bảng mã 7 bit chỉ đủ dùng cho tiếng Anh, trong khi đó nhiều quốc gia có các kí tự riêng, như tiếng Hy Lạp có các kí tự đ, B,Y; tiếng Nga có các kí tự 6, I, A. Do đó, người ta đã mở rộng bảng mã 7 bit thành bảng mã 8 bit gọi là bảng mã ASCII mở rộng, cho phép mã hoá 256 kí tự, trong đó giữ nguyên 128 kí tự cũ.
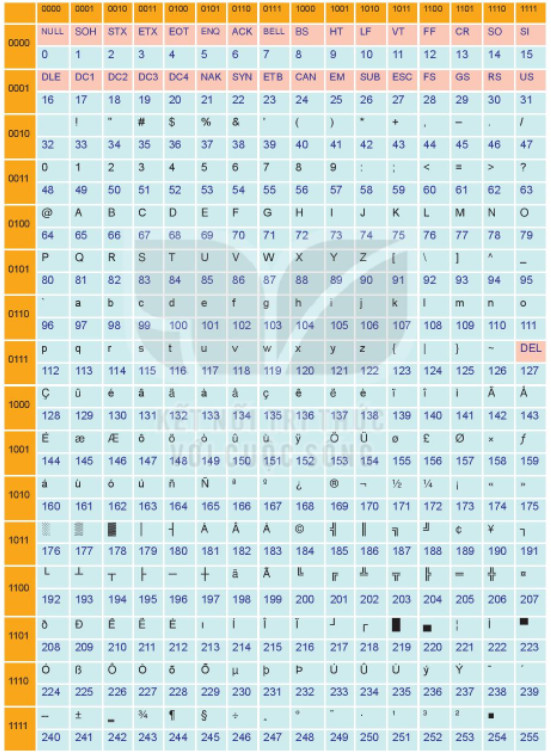
Bảng ASCII mở rộng
b) Bảng mã Unicode và tiếng Việt trong Unicode
Bảng mã Unicode:
– Unicode là bảng mã hợp nhất quốc tế, cho phép tạo ra các ứng dụng đa ngôn ngữ. Mỗi kí tự Unicode có thể được mã hoá bởi nhiều byte.
– Đầu những năm 1980, người ta đã đề xuất một chương trình quốc tế nhằm xây dựng một bảng mã hợp nhất dùng chung cho mọi quốc gia, gọi là Unicode.
– Unicode thực tế là một bộ tiêu chuẩn biểu diễn kí tự văn bản trong máy tính, cho phép sử dụng nhiều hơn 8 bit để biểu diễn các kí tự thuộc nhiều ngôn ngữ khác nhau trên thế giới.
– Ưu điểm:
+ Cho phép mã hoá hàng trăm nghìn kí tự khác nhau.
+ Tránh được tình trạng thiếu nhất quán do các quốc gia dùng các mặt chữ giống nhau nhưng mã khác nhau.
– Việc sử dụng Unicode tạo ra những ứng dụng đa ngôn ngữ, sử dụng đồng thời nhiều ngôn ngữ khác nhau như các trình duyệt web, ngôn ngữ lập trình, các phần mềm | ứng dụng, …
Tiếng Việt trong Unicode:
– Năm 2001 Việt Nam đã ban hành Tiêu chuẩn TCVN 6909:2001 về Bộ mã kí tự Tiếng Việt 16-bit để sử dụng chung. Tiêu chuẩn này hoàn toàn phù hợp với tiêu chuẩn quốc tế về Unicode.
– Năm 2017, Việt Nam cũng đã ban hành quy định bắt buộc sử dụng UTF-8 để biểu diễn bộ kí tự Unicode trong máy tính
⇒ Như vậy, hiểu một cách ngắn gọn, các bảng mã ASCII và Unicode quy định cách biểu diễn kí tự.
c) Số hoá văn bản
– Tệp văn bản là định dạng lưu trữ ở bộ nhớ ngoài.
– Việc số hoá văn bản được thực hiện bằng các phần mềm soạn thảo văn bản như Word (của Microsoft) hay Writer (của Open Office).
|
– Bảng mã ASCII mở rộng sử dụng 8 bit để biểu diễn một kí tự. – Unicode là bảng mã hợp nhất quốc tế cho phép tạo ra các ứng dụng đa ngôn ngữ. Mỗi kí tự Unicode có thể được mã hoá bởi nhiều byte. |
|---|