1.1. Bảng mã ASCII
Trong máy tính mỗi kí tự được biểu diễn bằng một dãy bit. Dãy bit này được gọi là mã nhị phân của nó. Để thống nhất cần có quy định chung.
– Quy định đầu tiên là bảng mã ASCII – là bộ mã chuẩn của Mỹ để trao đổi thông tin.
+ Bảng mã ASCII chứa mã nhị phân của bộ chữ cái dùng trong tiếng Anh và một số kí hiệu khác.
+ Mã ASCII của một kí tự là dãy 7 bit, có thể biểu diễn 128 kí tự khác nhau.
+ Ngoài những kí tự in ra màn hình còn có những kí tự không in ra màn hình (gọi là kí tự điều khiển)
+ Tham khảo tại: https://vi.wikipedia.org/wiki/ASCII
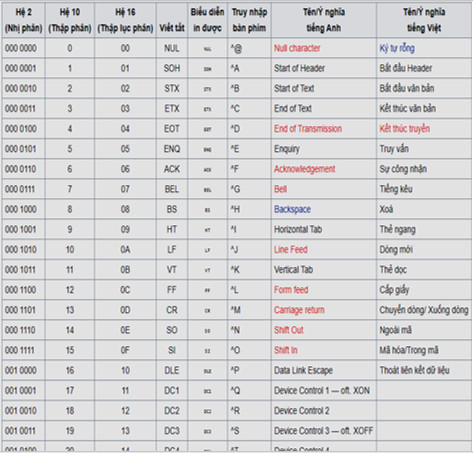
Bảng mã ASCII
– Bảng mã ASCII mở rộng: sử dụng mã nhị phân dài 8 bit, biểu diễn thêm được 128 kí tự nữa.
+ Mã nhị phân của những kí tự đã có trong bảng mã ASCII được thêm bit 0 vào trước để đủ độ dài 8 bit. Các kí tự mới thêm đều có mã nhị phân bắt đầu với bit 1.
+ Bảng mã ASCII mở rộng có thể biểu diễn 256 kí tự khác nhau
+ Tham khảo tại: https://vi.wikipedia.org/wiki/ASCII_mở_rộng
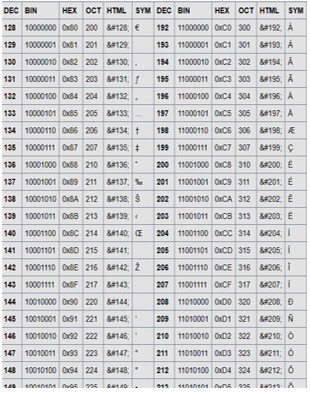
Bảng mã ASCII mở rộng
1.2. Bảng mã Unicode
– Bảng mã Unicode thống nhất chung việc mã hóa các kí tự cho tất cả các ngôn ngữ khác nhau trên thế giới.
– Tham khảo tại: https://vi.wikipedia.org/wiki/Unicode
1.3. Mã kí tự, bộ kí tự và mã nhị phân
Con đường đi từ các kí tự cho đến mã nhị phân của nó được chia làm hai bước:
Bước thứ nhất:
+ Cho tương ứng mỗi kí tự với một mã kí tự duy nhất, là một dãy kí số
+ Unicode gán 1 điểm mã duy nhất cho mỗi kí tự, kí hiệu, biểu tượng, … được dùng trong tất cả các ngôn ngữ khác nhau trên thế giới.
+ Mỗi điểm mã có 1 tên gọi. Ví dụ điểm mã U+1EC7 là của kí tự “ệ”
+ Mỗi điểm mã được gán một tên gọi duy nhất (không thể thay đổi nữa)
+ Không gian mã Unicode được chia thành các khối, một khối mã sẽ được dành riêng cho một ngôn ngữ cụ thể.
+ Ví dụ: Từ “Việt Nam” có các điểm mã Unicode như Hình 1

Hình 1. Các điểm mã Unicode trong từ “Việt Nam”
Bước thứ hai:
+ Chuyển từ mã kí tự thành dãy bit để máy tính xử lí được, gọi là mã hóa. Kết quả bước này là một dãy bit. Đây là mã nhị phân của kí tự.
+ Bảng mã Unicode chỉ thực hiện bước thứ nhất, sang bước thứ hai có nhiều cách triển khai thực hiện khác nhau.
+ Các bộ kí tự UTF-8, UTF-16, UTF-32 được hiểu là các chương trình thực thi khác nhau chuyển mã kí tự Unicode thành mã nhị phân
+ UTF viết tắt của từ tiếng Anh Unicode Transformation Format.
+ Số 8 nghĩa là dùng các khối 8 bit để biểu diễn một kí tự.
+ UTF-8 có khả năng mã hóa tất cả 1 112 064 điểm mã kí tự hợp lệ trong Unicode bằng cách sử dụng từ 1 đến 4 đơn vị mã 1 byte (8 bit).
+ Nó được thiết kế để tương thích lùi với ASCII: 128 kí tự đầu tiên của Unicode, tương ứng 1 – 1 với ASCII, được mã hóa bằng cách sử dụng 1 byte duy nhất có cùng giá trị nhị phân như ASCII. Văn bản hợp lệ ASCII cũng là hợp lệ UTF-8.
+ UTF-8 an toàn để sử dụng trong hầu hết các ngôn ngữ lập trình.
1.4. Dữ liệu văn bản và số hóa văn bản
Văn bản thần chữ (plain text):
– Chỉ gồm các kí tự gõ nhập từ bàn phím khi soạn thảo văn bản.
– Văn bản thuần chữ là một dãy các kí tự xếp liên tiếp từ trái sang phải, từ trên xuống dưới. Mỗi kí tự là một dãy bit.
Dữ liệu văn bản: Dữ liệu văn bản trong máy tính là một dãy bit biểu diễn các kí tự có kiểu dáng, màu sắc và các thông tin định dạng khác.
1.5. Kí tự tiếng Việt trong dữ liệu văn bản
– TCVN3: Là bảng mã tiêu chuẩn cũ của Việt Nam, dùng phông chữ có “.Vn” đứng đầu.
– Bộ gõ tiếng Việt Unikey khá phổ biến hiện nay có công cụ dễ dàng chuyển đổi các văn bản theo tiêu chuẩn cũ sang dùng mã Unicode để phù hợp với tiêu chuẩn mới.
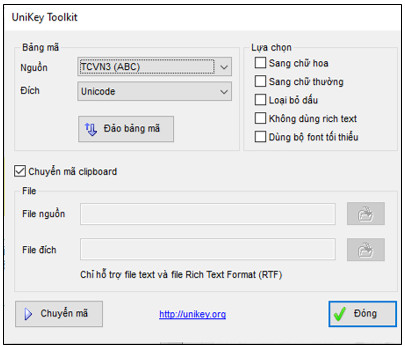
Công cụ chuyển đổi mã kí tự tiếng Việt trong bộ gõ Unikey
|
– Bảng mã kí tự ASCII mở rộng gồm 256 kí tự; mã kí tự ASCII chính là số thứ tự của kí tự trong bảng. – Bảng mã chuẩn quốc tế Unicode được thiết kế với mục đích thống nhất mã kí tự để máy tính có thể “viết chữ” của rất nhiều ngôn ngữ khác nhau trên thế giới. – Dữ liệu văn bản trong máy tính là dãy bit biểu diễn các kí tự cùng các thông tin định dạng. |
|---|